Megastore is a library on top of BigTable which provides app developers of the Google App Engine a convenient and traditional RDBMS flavor to develop applications. It is available on GAE since 2011 and being used on more than 100 production applications in Google, handling immense amount of reads and writes daily.
Motivation behind the development of Megastore is to please three different people - users, admins and developers. It should be highly scalable and so it uses NoSQL datastore, currently the most scalable technique. Admins want seamless fail over in case of planned shutdowns. To achieve this the replicas have to be consistent at all times, synchronous replication is done using Paxos. Finally satisfy developers by letthing them to code their application in simple and well known RDBMS+SQL style.
It is important to note that all the above mentioned requirements are conflicting.
Megastore achieves this by,
- Partitioning the data and replicating each partition separately.
- It then provides ACID semantics within each partition,
- synchronously replicating across geographically separated data centers for high availability
Data Model & BigTable layout
It is declared in a schema and is strongly typed. Tables - > Entities -> Properties
Primary key is one sequence of these properties for that Entity, and are unique for that table.
Tables are again classified as root tables and child tables( which have a foreign key referenced into the Root table). Root entity and associated child table entities form a Entity Group. There can be different classes of entity groups.
Mapping to BigTable
Primary key values are concatenated to form BigTable row key, and the properties as columns(TableName.PropertyName). There will be a bigtable row for each entity. Keys should be chosen smart enough to cluster entities that will be read together.
Local index is created for each entity group and are updated along with the data in the entity group. Global index is also present which is sometimes not consistent as it spans across entity groups. Index entries are again a BigTable row with the row key being indexed property values concatenated with primary key of the indexed entity.
A write ahead log is maintained with each entity group. Each entity group is synchronously replicated across data centers by replicating this log of the entity group.

If the local replica is not up-to-date , find the highest log position from majority of other replicas do a "catchup" to get the log and update the current replica. It then sends the coordinator a validate message to assert that replica is up to date and then perform the actual read.
Megastore provides three levels of read consistency -
There are bunch of replicas called Read-Only replicas, contain full snapshots of the data may not be up-to-date but useful for the applications which can tolerate stale data. These are used for Snapshot Reads.
Paxos with leaders - Traditional usage for locking, master election, replication of metadata and configurations. Megastore uses paxos for across data center replication and high availability. Megastore introduces a concept of leaders, a leader is the replica which was successful in the previous log position consensus.
Mapping to BigTable
Primary key values are concatenated to form BigTable row key, and the properties as columns(TableName.PropertyName). There will be a bigtable row for each entity. Keys should be chosen smart enough to cluster entities that will be read together.
Local index is created for each entity group and are updated along with the data in the entity group. Global index is also present which is sometimes not consistent as it spans across entity groups. Index entries are again a BigTable row with the row key being indexed property values concatenated with primary key of the indexed entity.
A write ahead log is maintained with each entity group. Each entity group is synchronously replicated across data centers by replicating this log of the entity group.
Architecture
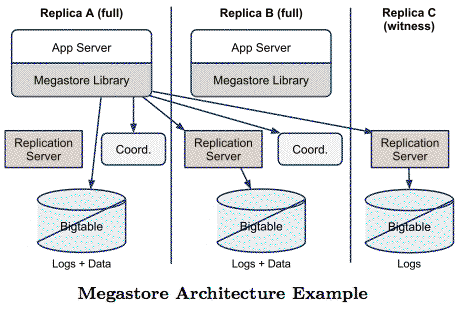
Reads and Writes in Megastore
Read
A coordinator server provisions for local reads at a replica. It keeps track of the entity groups to be up to date. So a read starts querying local replica coordinator to check if the replica is up-to-date. It then reads the highest applied log position and time stamp from the local replica. With this timestamp it read from the BigTable.If the local replica is not up-to-date , find the highest log position from majority of other replicas do a "catchup" to get the log and update the current replica. It then sends the coordinator a validate message to assert that replica is up to date and then perform the actual read.
Megastore provides three levels of read consistency -
- Current Read: Application reads at the timestamp of the latest committed and applied transaction
- Snapshot Read: Reads from the last applied transaction, there might still be some committed transactions not applied yet
- Inconsistent Read: Just read from the top for application which do not tolerate any latency.
There are bunch of replicas called Read-Only replicas, contain full snapshots of the data may not be up-to-date but useful for the applications which can tolerate stale data. These are used for Snapshot Reads.
Write
Paxos with leaders - Traditional usage for locking, master election, replication of metadata and configurations. Megastore uses paxos for across data center replication and high availability. Megastore introduces a concept of leaders, a leader is the replica which was successful in the previous log position consensus.
A write starts with next unused log position and getting the timestamp of the last write. Current replica packages the changes to the state and timestamp as the consensus value for the next log position and nominates itself for next leader position and proposes to the leader. If successful this change is update at all replicas or else the transaction is aborted and retried. Replicas which did not accept get a invalidate message to their coordinator to update their state.
To achieve this quorum during writes there are set of replicas called Witness Replicas. These are different from full replicas , as they do not maintain actual data and do not have a coordinator. They just have the log and therefore participate in consensus and help to achieve a majority vote for replicas to make the write successful.
To achieve this quorum during writes there are set of replicas called Witness Replicas. These are different from full replicas , as they do not maintain actual data and do not have a coordinator. They just have the log and therefore participate in consensus and help to achieve a majority vote for replicas to make the write successful.
Conclusion
This paper is highly technical and gives a lot of details on Megastore's architecture and implementation. Using BigTable as the NoSQL datastore and providing ACID semantics on top of it is a very novel idea. Modifying Paxos to suit for the requirement here is another good takeaway from this paper. The results show very good performance in production applications. Five 9's availability shows good promise for others to use similar architecture.Discussion points
- Design decision: Limiting the writes to few writes per second.
- Latency vs Strong consistency requirements in Megastore.
- NoSQL vs relational databases, how long can the developers be using traditional style?
- Will ACID semantics remain forever?
Interested Readings:
- James Hamiltons blog
- The paper Life beyond distributed transactions by Pat Helland is mentioned in many blogs/discussions that I have checked out
- Google app engine blog